
If your organization logs 3,000 IT tickets a month, you’re not running IT. You’re managing disruption at scale.
Most enterprises don’t realize this.
They look at ticket volumes as a sign of activity. They measure resolution times.
They celebrate SLA adherence.
But none of these answers the only question that matters to a CFO: What is the real cost of these tickets to the business?
More importantly, where is this cost reflected in your P&L?
In most organizations, it isn’t. It quietly erodes EBITDA through reduced workforce productivity without ever being explicitly measured.
Let’s put numbers to what is usually invisible.
Industry data suggests that nearly one-third of help desk tickets result in “stop-work” situations where employees cannot continue their tasks until the issue is resolved.
I am taking an example to illustrate the point. For an enterprise generating 3,000 tickets per month, that translates to:
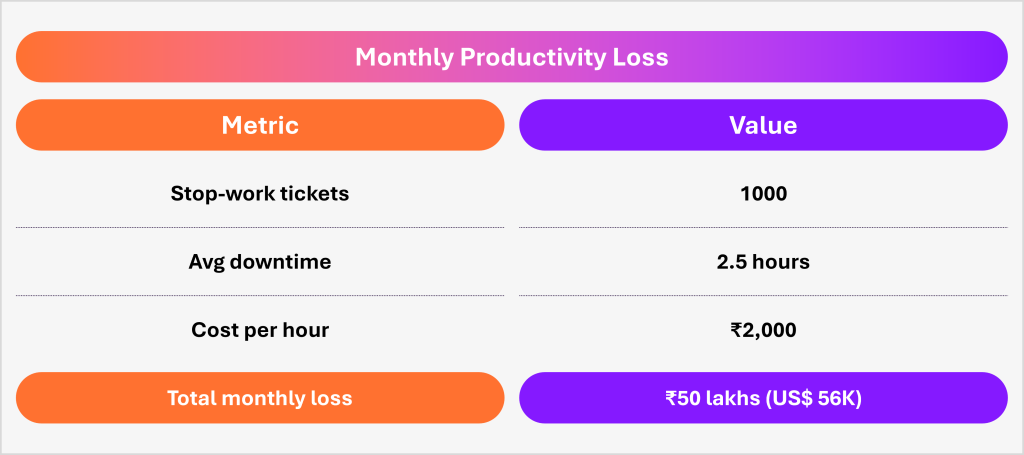
Annual impact: ₹6 crores (~US$ 700K)It assumes:
Reality is messier and more expensive
In practice:
Which means the actual impact is closer to:₹70 Lakhs to ₹1 Crore per month in productivity loss
And this is conservative. This does not include:
The helpdesk is not a support layer. It is a silent financial drain operating at scale.
Most CIOs already know ticket volumes are high. What they underestimate is why the system never improves.
Every ticket is resolved in isolation. Very few organizations ask:
Dashboards, monitoring tools, and automation scripts; there is no shortage of visibility.
But visibility ≠ understanding.
More tools have created more noise, not better decisions.
Even when signals exist, decisions lag:
By the time action happens, the business has already absorbed the cost.
Your best IT operators know:
But this intelligence is:
So, the system resets every day.
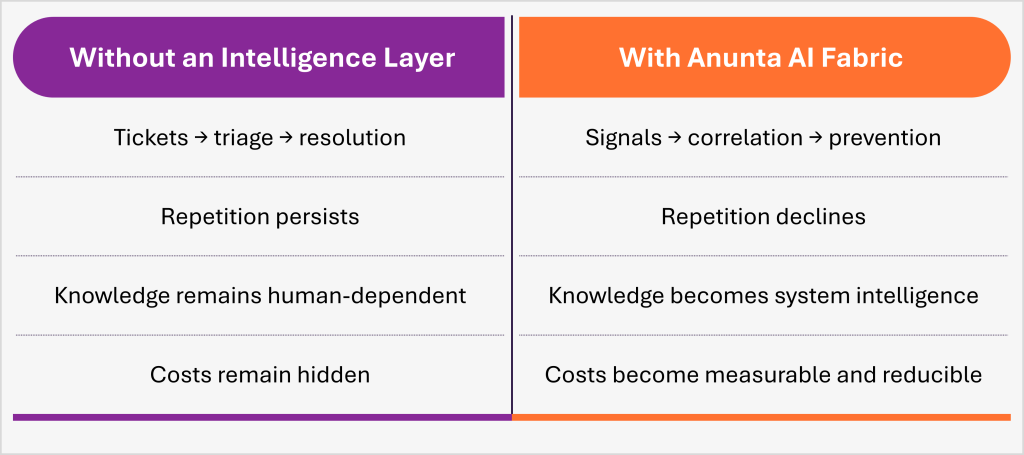
Most enterprises are still running Ticket-Driven IT, where:
This model was built for stability at a low scale.
It breaks at enterprise scale because:
And one assumption continues to hold this model together:
SLA adherence equals performance
It does not.
SLA adherence measures how efficiently disruptions are processed, not how effectively they are prevented.
The shift required is fundamental.

This is where a new layer is emerging in enterprise IT.
Not another dashboard. Not another automation tool.
But a system that can:
This is the direction in which leading organizations are moving.
Because the goal is no longer to manage tickets.
It is to reduce the conditions that create them.
Most AI conversations in IT focus on automation. That’s not the real problem. Automation without context simply accelerates the wrong actions.
What enterprises actually need is:
A system that decides what should be done, before deciding how to do it
This is the role of Anunta AI Fabric. Within an active IT environment, it functions as:
It connects signals across:
So, incidents are understood as patterns, not isolated events
It reduces decision latency by:
It captures how experienced operators think:
And makes that intelligence reusable across the system.
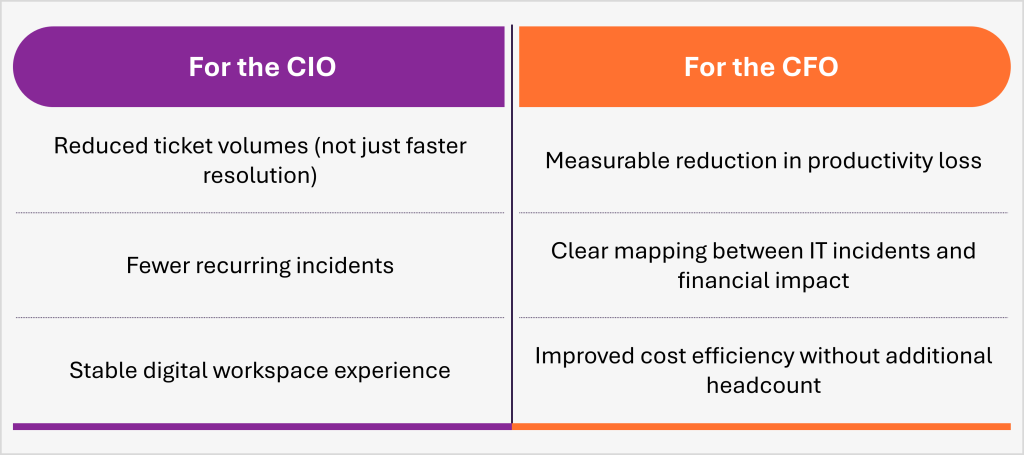
If you’re managing IT at scale, ask three questions:
If you don’t have clear answers, you’re not managing IT performance. You’re managing IT activity.
The future of enterprise IT operations will not be defined by:
It will be defined by:
How quickly your environment can understand itself and act accordingly
As enterprises scale:
Ticket volumes will not stabilize. They will increase. And so will the cost of inaction.
At 3,000 tickets a month, the question is no longer:
“How do we resolve tickets faster?”
The real question is: “Why do these tickets exist at this scale, and what is it costing us?”Because until that question is answered:
Start with a Ticket Economics Audit:
Most organizations lack the visibility to run this analysis internally. That is precisely why this step is critical.
And then ask: What would it take to move from reacting to incidents… to preventing them altogether?
That is the shift from tickets to intelligence
And that is where the next phase of enterprise IT is being built.



